This is part 6 of our 8 SEO Gifts for Chanukah series breaking down some basics of Search Engine Optimization.
What happens when you want to buy the new Bella Electric Triple Slow Cooker – Red? Well if you are like me you go into Google and type Target Bella Electric Triple Slow Cooker – Red”
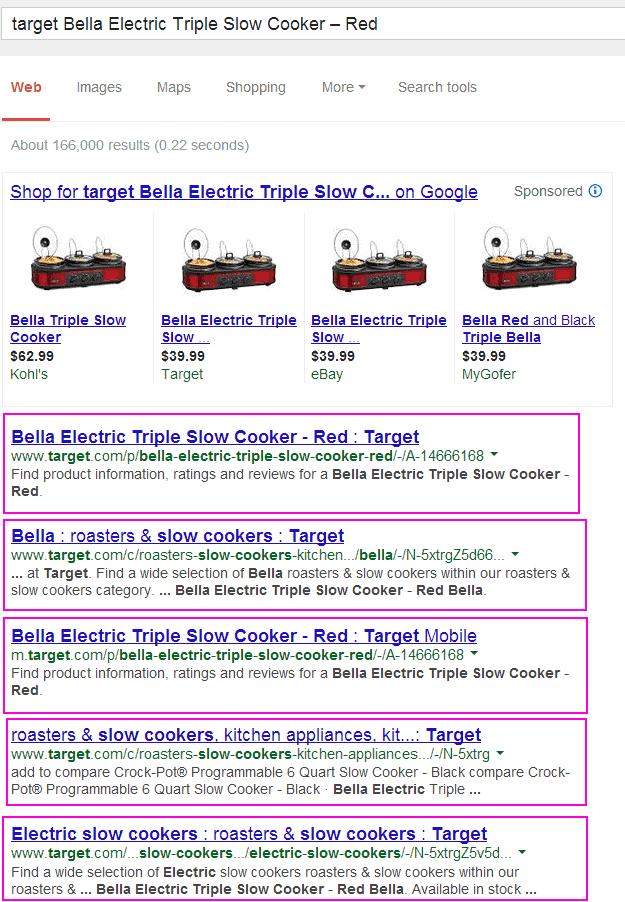
So What Exactly is Index Bloat?
An index bloat is one of the most common problems websites (typically ecommerce sites) encounter. Given that majority of sites either have issues with pagination or filters due to various sizes and/or colors of their products – search engines become confused and tend to index all the various landing pages deemed relevant. In many of these cases, the pages should not be indexed but there is no way for the search engine to understand what they should or should not show in the index. So they show everything, sigh.
Uh Oh – My Content Isn’t Showing!
In many instances when the search bot is overwhelmed and unclear what content to show – it might not show anything! When websites were first built it was quite simple: Page A led to page B and page B let to page C. Nowadays, with the simplicity of CMS systems and various folders, sites can have multiple paths that lead to the same content. Page A can lead to Page B which leads to C which also leads to E and A and D and so on. A dress can be found in a sale section, dress section, and in summer clothes. Each section has the same item but with a different subfolder host that the search bot reads and prepares to index.
The problem occurs when multiple products end up in multiple categories and the search bot gets lost in the endless routes ending in repeating products. When it comes down to it, the search bot just needs to know the pages on the site, not the multiple routes that it takes to get to the same page.
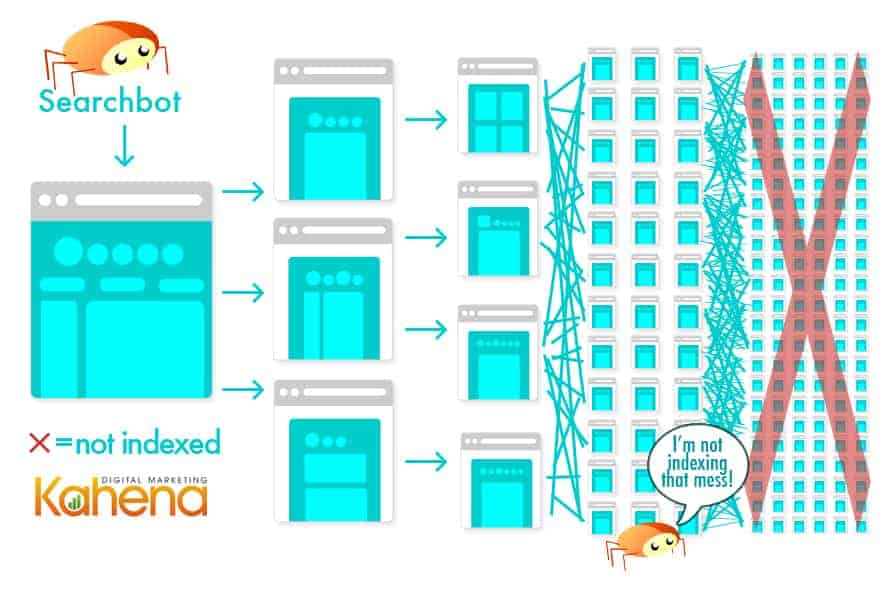
It is important to note that from a user standpoint, the ability to find products on a site by specifying certain parameters (like size, style and color) is an awesome organizational tool to have. But, the concepts “user friendly” and “search engine friendly” are not one in the same. To have a user friendly site that is also search engine friendly, you will need to take some extra steps in the development and coding of your site so that the users can have parameters to find the right products, but the search bot is presented with a more streamlined view of the same products.
So, What Can I Do To Fix This?
Luckily we have a few options to identify and clean up a site’s index to consolidate link equity to help strengthen the page’s ranking and relevance for related keywords.
Canonical Tag
A canonical tag is a special code used read by search engines and bots to differentiate between the preferred version of a page or a page that is highly similar. By placing a canonical tag in the header of your site you are in essence telling the search engine bot to only index the preferred version of a page.
The Canonical tag is placed on the non-preferred version with a link to the preferred version of the site.
- Quick Copy Paste: <link rel=”canonical” href=”http://www.preferedversion.com” />
- A live example of this is on Gap’s homepage. They have placed a canonical tag on all variations of their homepage so that the search bot will be rerouted to the preferred version of the homepage and not get lost in superfluous homepages they’ve created for users.

Note that canonical tags only affect the search bot’s crawling and indexing of the site, but do not interfere with the user’s interactions once they are navigating through the site.
Redirect
In some cases, the index is over-bloated for a particular site due to old pages that are actually resolving as 404 error pages when you click on a link. If a site decided to change their folder structure from dates to category names or something similar, it is possible that both the old and new URL are currently indexed. In this case, it is best to redirect the old page to the new page to give the visitor the best user experience and the content they are actually looking for!
To learn more about redirects, check out our blog on http status codes!
Webmaster Tools
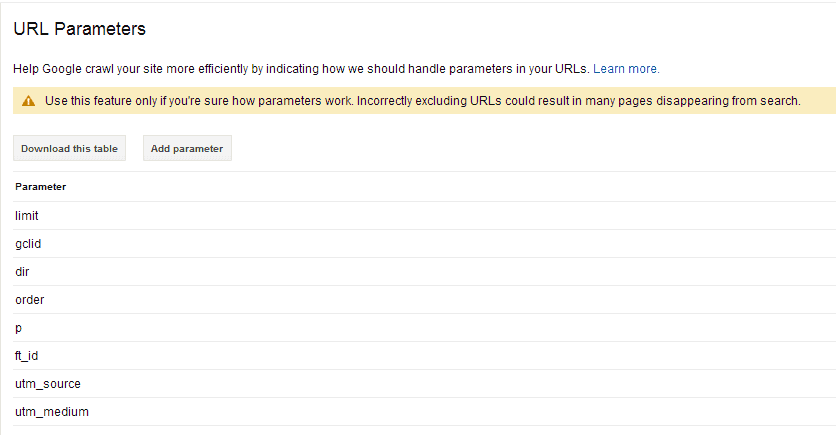
Google’s Webmaster Tools now allows site owners to decide for themselves how they want the various parameters to show in the site index. As shown in our previous post on URLs, parameters allow the search engine to understand how to display a particular page or to capture cookie or other unique information about a campaign or user. By defining particular parameters you are manually answering the search bot’s query on why the content may appear more than once.
**Be Careful Though! Google has issued a strong warning that you can accidently de-index too many pages so only use this feature if you understand exactly which pages you do and do not want to show.
Pagination
Pagination is a form of duplicate content that occurs when an article is more than 1 page long or when a product list spans across more than 1 page that most likely has duplicate title tags and meta descriptions. In order to explain the relationship between sequential pages of similar content, we can add a special code to a site header to equate the relationship of various pages. By adding the code rel=”” or rel=”prev” to the connected pages, search bot will be able to recognize the relationship and index or not index accordingly.
Block Robots from Thin Content
Use meta robots tags and robots.txt to ‘noindex’ thin content pages like search pages, category or tag archives, and/or other thin content. Check out our blog post on search bots for a great overview on how to control site crawlers.
Now that we have cleaned up our index we shouldn’t be surprised to easily find our triple slow cooker in red. Just in time for winter!